


З появою штучного інтелекту процес копірайтингу, тобто написання текстового контенту для потреб замовників, докорінно змінився. Тепер достатньо зібрати невеличку «базу даних» для нового проєкту, що складається зі «статей-донорів» — на основі яких буде написана наша стаття. Після цього підібрати ШІ-модель і поставити їй правильні запитання. Останнє є перспективним напрямком — дехто навіть називає промпт-інжиніринг професією майбутнього.
Сьогодні ми поговоримо про те, як можна зменшити час на підготовчу роботу — копіювання тексту з сайтів-донорів. Просунуті користувачі напевне здогадалися, що говорити будемо про процес парсингу.
Простенький парсер на Пітоні та штучному інтелекті
Я закінчував фізмат, проте не є професійним програмістом, маю про процес програмування доволі поверхове уявлення. Тому вирішив спитати у штучного інтелекту — напиши мені парсер, який буде забирати статті по заданим URL і класти їх у наперед визначену папку.
Скажу відразу – вийшло не відразу. Спочатку ШІ видав таке:
Скрипт не запускався – виявилося що в терміналі треба було запустити 2 команди:
pip install requests
pip install beautifulsoup4
Далі – була помилка ConnectTimeoutError. Сервер скидав з’єднання раніше, ніж парсер встигав скачати статтю.
Штучний інтелект запропонував покращення:
response = requests.get(url, timeout=10) # Устанавливает тайм-аут соединения на 10 секунд
Були проблеми з відображенням: скачані статті відображались «крякозябрами».
Рішення – явно вказати кодування:
def parse_article(url):
response = requests.get(url)
response.encoding = 'utf-8' # Явно указываем кодировку как UTF-8
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('h1').text.strip()
paragraphs = soup.find_all('p')
text = '\n'.join([p.text.strip() for p in paragraphs])
return title, text
Наприкинці вийшов такий результат:
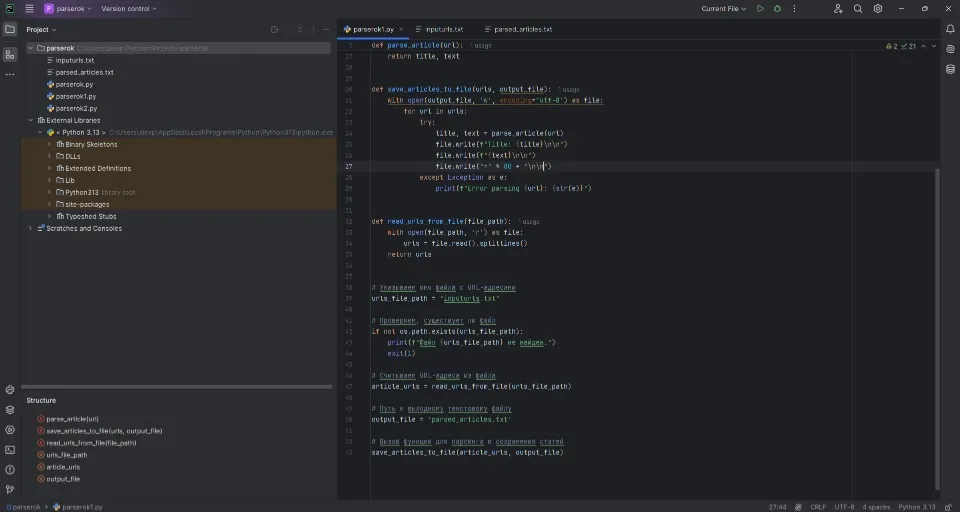
Що потрібно ще зробити?
Для того, щоб вся ця «машинерія» працювала, потрібно створити новий Python-проєкт в програмі PyCharm. В каталозі проєкту створити 2 текстові файли – inputurls.txt та parsed_articles.txt. В перший файл покладіть посилання, з яких треба спарсити статті, а у другому — будуть статті з ваших донорів.
Для чого це все потрібно?
Скриптом я парсив гороскопи, місячні календарі та прикмети на кожен день. Далі це все надсилається в ШІ, формується промпт — і на виході 1 змістовна, а головне корисна для користувача стаття.
Скрипт економить час, який потрібен на копіювання тексту з донорів. Наприклад тут більше 2 десятків посилань. Копіювати все це вручну доволі нудно).
І ще — робота скрипту на інших сайтах, крім вказаного, не гарантується. Мета цієї статті показати, чого можна досягти за допомогою синергії програмування та штучного інтелекту. Ба навіть більше — якщо добре розуміти програмування, то й гори можна звернути). Чекаю на ваші коментарі!


